
Gary LaFever (Anonos)
[45:47] Thank you, Gwendal. So, we've had quite a few questions submitted. We likely will not have a chance to answer them all during the live webinar, but I encourage you to continue to submit questions through the web interface and also to questions@bigprivacy.com because everyone that's registered will get a copy of the questions and answers. Also, a couple of questions have come through and they have asked questions that I think deep answers are in the whitepaper that we referred to before. So, if you want to refer to that as well, again, that's www.anonos.com/whitepaper, but we will answer all of them and everyone on the webinar will get copies.
[46:24] So, what I'm going to try to do to try to get as many of these questions as possible is group a couple of them. So, I'm going to read three questions that are a little different, but I think all deal with the same issue. First question: “Most businesses are focusing only on bare minimum tick-in-the-box exercises rather than using this as an opportunity to transform the way they manage and use personal data. What would your advice be to them?” Next question: “How do I make our technologists understand why we have to process data differently the day that GDPR goes into effect than the way our company has processed data for years prior to the GDPR?” And the last one of this set: “My company’s technologists use the lack of specific requirements and specifications under the GDPR as an excuse not to change what we do and how we do it. Any suggestions?”
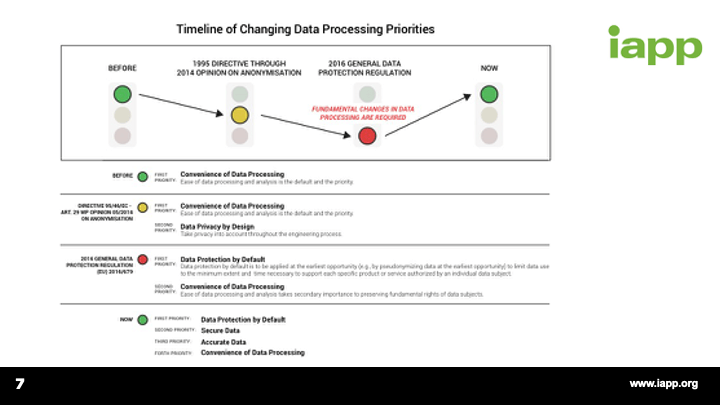
[47:22] I'll start with this and then hand it over to Mike and with Gwendal. But I think this is actually a very important set of questions and I think this is a wake up call. The GDPR is not a rule that enables you to make minor changes. It requires a fundamental shift, hopefully, that that one slide with the stoplights helps to convey that. It does require data protection by default, which has never been required before. Or if required, the penalties have been so de minimis that people just basically engaged in regulatory arbitrage and paid the fine.
[48:00] The penalties are currently assessed at 4% of global gross revenues, and it doesn't get as much press, but there's also joint and several liability between data controllers and data processors. So, the magnitude of fines could be amazingly large. And I believe and Gwendal can speak to this that the reason they are like that is because the EU legislators and regulators want us to take the rights of data subjects seriously. And that hasn't always been the case.
[48:26] So, the bottom line is you need to start the interaction with the downside of not complying and that does require that the people on this call likely are the standard bearers who are saying: “This isn't something we can just do a check the box.” But that's why we added the new slide four to the deck. If you take to them what these changes could mean in a positive way, you'll get more engagement by management on a different approach. This will likely require changes to architecture. Technologists hate that. You need to show them it's no longer discretionary, it's no longer optional, and they need to be at the table together with you and together with the people who are responsible for generating revenue and value through data. And through that stakeholder group, you can have a productive discussion. And so, Mike, do you want to take that just to kind of give your perspective on those three questions?

Mike Hintze (Hintze Law)
[49:22] Yeah. You know, I agree with what you said. I think that there's a temptation and a natural reaction in many cases to say: “Well, you know, we haven't been handed a clear roadmap by the regulators that we have to take steps one, two, and three, and it's all very amorphous. And so, we're just gonna throw up our hands and do nothing.” And that's exactly the wrong thing to do at this point. It still seems like May 2018 is a ways out, but it's really not given the types of things that need to be done to get ready for the GDPR. I know a lot of companies have already done that path, a lot of companies are just getting started, and others are just trying to wrap their heads around what this all means. But companies need to start doing something. They need to start putting steps in place that when the regulator comes knocking after May 2018, they can say: “Look, these are the things we did.” And you know, at the end of the day, there's going to be some uncertainty and things are going to have to be tweaked as more guidance comes out as the GDPR starts to be enforced, and we all collectively start to understand what it's going to look like in practice better. But taking the steps to deal with the process and taking in the steps to deal with the data and how data is managed, stored, and processed - those are going to be important steps that have to be started now because you can't just flip a switch and do that overnight. You can't just wake up in, you know, April of 2018 and say: “Oh, well, now it's time to get GDPR compliant.” It's gonna take some time.
Gary LaFever (Anonos)
[51:11] Gwendal, do you have any perspective on this you'd like to share?

Gwendal Le Grand (CNIL)
[51:15] Yeah, maybe if I can add to it that GDPR is applicable in May 2018, as you say, so that means we have more or less 15 months left, which is not a lot of time because there's a couple of things that need to be changed in your organizations concerning the governance of privacy, I would say. So, it's clear that companies need to get prepared. There's also new rights for individuals. It's not the topic of our webinar today. But for instance, there’s a new right to portability. There is an obligation in certain cases to conduct a DPIAs (Data Protection Impact Assessments) within the companies. There is an obligation to notify personal data breaches to the authority and to the data subject. This is feasible. Companies who process privacy and who take privacy into account properly will be ready for the GDPR, but they need to think of this a little bit in advance because new processes need to be implemented in place in the company.
[52:23] And one important thing I think is, of course, the fines can be a bit scary for the companies because it goes up to 20 million Euros or 4% of the annual turnover and the highest amount that counts. So, it's actually for big companies we are talking about 4% of the worldwide turnover of the company, but it also gives a lot of leverage to privacy professionals to get and to have more engagement by the management because when you're trying to implement some privacy safeguards and some security safeguards in your systems, I mean the order of magnitude is changing completely with GDPR. So, I think it's a very interesting tool for privacy professionals. And this is really how they have to see it.
[53:10] The last point I want to make with respect to the questions is the fact that Article 29 and the group of regulators is trying to help you also with respect to the implementation of GDPR. We've already issued some guidelines in December on a number of topics including the right to portability that I mentioned before and also Data Protection Officers. These guidelines have been open for comments and we're still receiving a lot of comments by various organizations. The deadline for comments is today, and we will produce some guidelines and other topics on the hot topics to help companies be ready for the GDPR in 2018. This will be announced shortly. Now that we've issued some guidelines on certain topics, we'll be working on a new set of guidelines and this will be done over and over again until May 2018 when the GDPR is applicable.
Gary LaFever (Anonos)
[54:13] Thank you, Gwendal. Please continue to submit questions through the sidebar on the webinar interface and also to questions@bigprivacy.com. We will commit to answer two more questions that have been submitted. But as we said, the rest of them will be answered within the next week. So, please do not stop submitting. So, this question goes as follows: “US law focuses on whether identifiers are directly linked to data subjects. The EU laws focus on whether identifiers are linkable to data subjects. The GDPR requires appropriate technical and organizational measures to safeguard the rights of data subjects. Does this mean that persistent identifiers are not permissible under the GDPR?” Gwendal, do you want to start with that one?
Gwendal Le Grand (CNIL)
[55:06] The GDPR is a framework to explain in what conditions you can process personal data. It's not a ban on the processing of personal data. It just says: “You can process personal data, but you can process personal data under certain conditions.” And these conditions are the privacy principles which are described in the relevant article of the GDPR, one of which is security that you mentioned before. So, Pseudonymisation, anonymisation and also other measures can be implemented. There's this principle of the risk based approach, so you need to understand what security safeguards you need to implement in the system based on the risks that your processing is facing, but it’s not preventing the processing of personal data per se. The only thing that it’s saying is that the GDPR does not apply to data that is made anonymous.
Gary LaFever (Anonos)
[56:18] To follow up very quickly and then I’d love to get Mike's perspective. The problem with persistent identifiers is: “Who has access to those persistent identifiers? And how likely are they to be subject to linkage attacks of the mosaic effect?” And so, like Gwendal says, the GDPR is not intended to stop the processing of personal data, but rather you're supposed to put in place protective measures, both organizational and technical, to make it harder. So, Mike, do you have further clarification on that?
Mike Hintze (Hintze Law)
[56:46] I guess the way I would respond to the question is that persistent identifiers are not barred under the GDPR. No type of data is barred. Any day they can be processed. But if you're using data that meets the definition of personal data, and it is not de-identified in any significant way, all of the requirements of GDPR are going to apply to you. If you use an intermediate level of de-identification, if you meet that level that's described under Article 11 that I talked about earlier, you get some relief if you use any method of de-identification that’s at least showing or at least partially showing that you have adopted the kinds of measures that are required under the GDPR. But it's not the only way that you can comply with the GDPR. And if you get to the very highest level of de-identification and it meets the anonymisation bar that Gwendal described then you get sort of complete relief from the GDPR. So, it's a spectrum. But there's nothing that's absolutely barred. It's just a matter of compliance obligation you provide to that data based on the nature of that data.
Gary LaFever (Anonos)
[58:05] Gotcha. So, one last question quickly. We appreciate everyone staying with the webinar, and we'll go long enough to get this question fully answered. I'm going to group two questions here. The first one is: “Can you suggest how to get a budget for GDPR compliance in 2017 when senior management views GDPR as a 2018 issue?” And then the second one: “As chief privacy officer, my title has a “C” in it but that does not mean I have a key to the C suite. The magnitude of liabilities and obligations under the GDPR are way out of sync with budget and authority that I have in my position. How do I navigate the corporate labyrinth to make senior executives fully appreciate the magnitude of these issues?” Mike, you want to take a first shot at that?
Mike Hintze (Hintze Law)
[58:55] Yeah, sure. I think it comes back to some of the things we talked about earlier in response to the first group of questions. And that is, you know, you need to make the case that the time is now to be focusing on the GDPR. Like I said before, the types of things that need to be put in place to show compliance with the GDPR are not things that you can just flip a switch or turn on a dime. They require investment now and over the next year. So, sort of laying that out showing the types of things that need to be done, the type of architectural changes that may be required, the type of process changes, the type of organizational and personnel and training things - these all take time and they require investments of time and money currently. And if you're waiting until 2018 to do that, there's just not going to be enough time to get it done.
Gary LaFever (Anonos)
[1:00:00] Gwendal, do you have any particular insight?
Gwendal Le Grand (CNIL)
[1:00:02] Yeah, I can add to this as well. Of course, as I said before also, there are new rights for data subjects. There are new processes that need to be implemented in companies. And it just takes time to be prepared adequately so that companies are ready. And two important triggers that you can find in the regulation are Article 3 and Article 83. Article 3 is about the territorial scope. So, it says that the regulation applies to controllers and to processors regardless as to whether the processing is taking place in the Union or not. So, if you have an establishment, or if you're targeting basically users that are in the EU, then the GDPR will be applicable to you. So, that's the first thing. So, it means it's applying to many people that you are offering your services in Europe, you need to take into account GDPR.
[1:01:02] The second thing is Article 83. Article 83 is about the fines. So, I mean, everyone has heard about this. But if you go to your management and you say: “Well, the risk that we run as a company if we're not prepared to do GDPR is this amount of money.” I think this gives you a lot of leverage when you discuss with your management. So, it's not a very nice way to discuss with your management, but I guess it's very efficient.
Gary LaFever (Anonos)
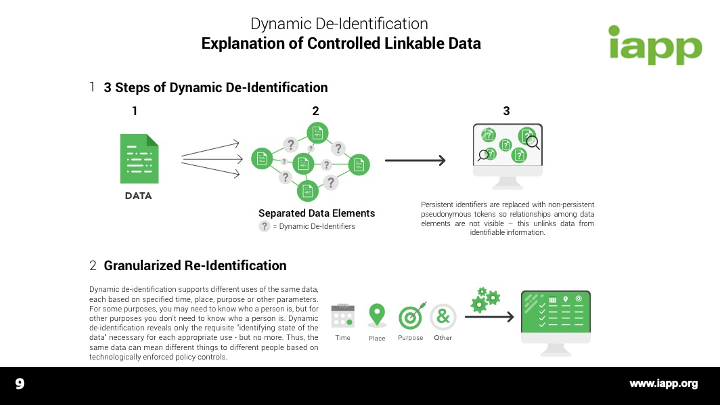
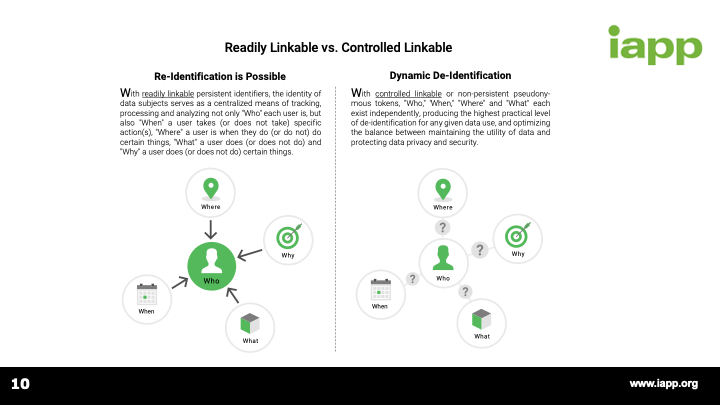
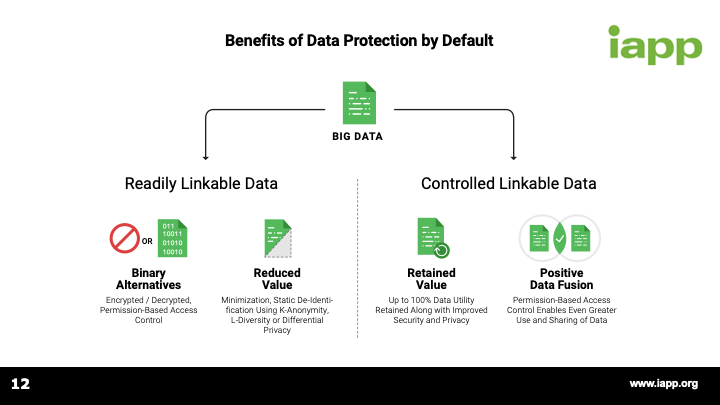
[1:01:36] Great. So, again, I appreciate everyone's questions. Please continue to submit through the webinar interface and also questions@bigprivacy.com. I think it’s evident just from what we were able to do during the live session we're clearly at a tipping point, and companies can really no longer do what they used to do and expect to comply with the GDPR. They have to look at what steps they're taking to protect the rights of data subjects based on the uses of the data that they're making. Again, I would encourage you to take a look at Mike's earlier de-identification whitepaper, as well as the one that he and I recently wrote on big data and controlled linkable data.
[1:02:20] Clearly, readily linkable data and linked data and persistent identifiers, the way they've been used in the past can no longer be used quite the same way. You have to have protective mechanisms in place and show that you're giving controls to the data subjects and you're respecting their rights and this requires new technical measures. Data protection by default did not exist prior to the GDPR. And as Gwendal just said, if you think about what's changing on May 25, 2018, it's really as much if not more about the fines as it is the requirements but with the magnitude of those fines and the potential penalties and the opportunity to embrace new technologies to improve business practices. Hopefully, this is truly a tipping point, which is not a negative. It's a positive.
[1:03:06] So, while things like persistent identifiers can't be used as readily as they have in the past, there are ways to continue business processes so that everybody can be successful. And we would like to think and I know the IAPP has this mindset that 2017 is a year about talking about solutions and approaches and working together to make things happen. We invite people to continue to submit questions and be active through the follow on to this live webinar. And you will receive by the end of today, a copy of the deck that was presented today. And within the week, you will get a copy of all the questions and answers as well. So, thank you very much. I want to thank you, at least on our part, and I'll turn it over to Dave.

Dave Cohen (IAPP)
[1:03:47] Well, thank you very much, Gary. And let me echo from the IAPP our thanks to Anonos for sponsoring today's program and making all this great information available for free to our attendees. And of course to Mike and to Gwendal who were with us today. It's really a pleasure to have both of you on the panel and to work with you in preparing for this, and we very much appreciate your time, effort, and energies to help strengthen the privacy and security community that we're all building together here as we lead up to the compliance deadline for GDPR.




















 62 min
62 min


